2. TOAR Data Centre Infrastructure Components
This section details the infrastructure’s systems and services as well as software, backup and other implemented housekeeping functions.
2.1. Description of System and Service Components
The TOAR Data Centre infrastructure consists of four main products and services (Fig. 2.1). These are:
the TOAR data portal — a one-stop-shop to locate and access tropospheric ozone data from a large variety of measurement platforms (https://toar-data.org),
the TOAR web services — an interactive GUI (graphical user interface) for the online analysis of station-based surface ozone measurements and related variables (https://toar-data.fz-juelich.de/gui/v1 | v2) 1 together with a REST API (representational state transfer, application programming interface) (https://toar-data.fz-juelich.de/api/v2 resp. https://toar-data.fz-juelich.de/api/v1) which allows for machine access to ozone data and ozone analyses,
the TOAR database of station-based ground-level measurements of ozone, ozone precursors and meteorological variables. This database also contains meteorological variables from weather models. Access to the data is provided via the TOAR web services,
the TOAR data publication service enables the TOAR data curators to publish data sets to the external service B2SHARE at FZJ (https://b2share.fzjuelich.de/communities/TOAR). B2SHARE offers trusted long-term publication of ozone data sets as well as TOAR analysis products and it includes DOI (digital object identifier) assignment with Datacite.
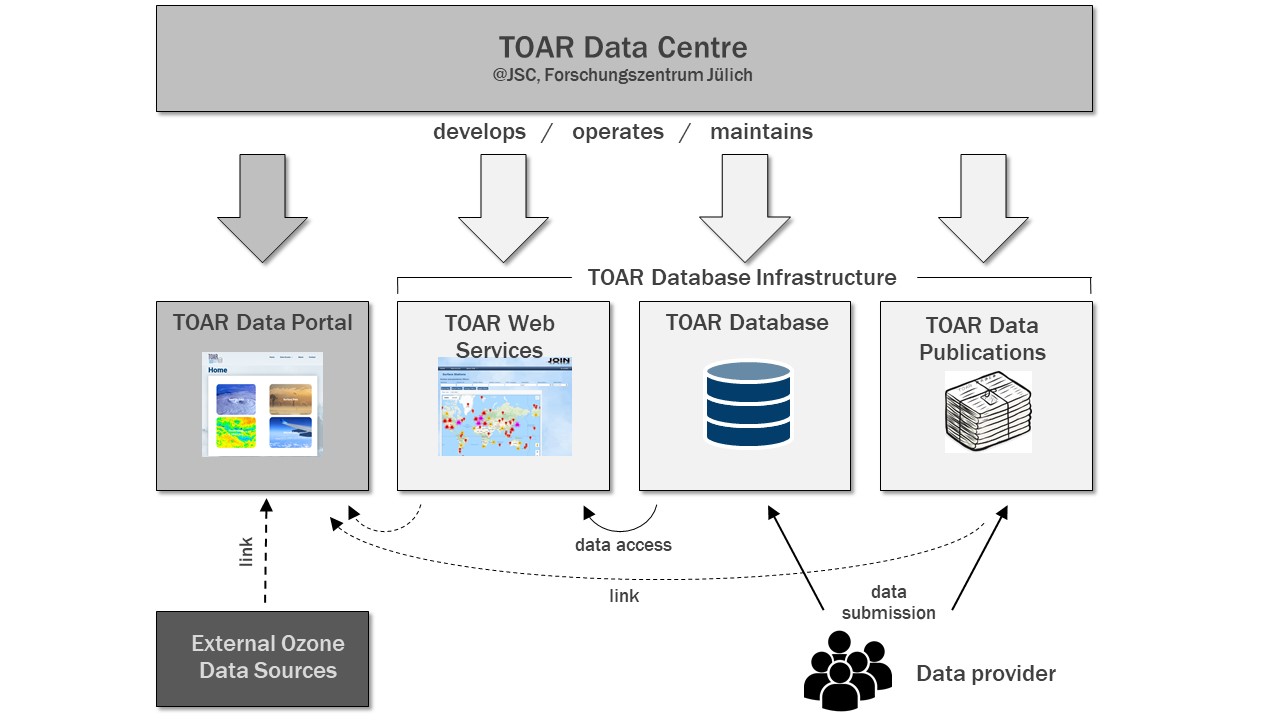
Fig. 2.1 The TOAR Data Centre infrastructure and its main service components
In addition to these four core services several other services are running in the background. These are local instances of EUDAT’s B2SHARE, OpenStreetMap, and different geolocation services. In addition, software has been developed for the data ingestion workflow which is at the heart of the TOAR database.
The servers housing the services are Virtual Machines (VM) in OpenStack and VMware clusters at JSC or systems at third party providers.
The following sections describe the individual service components, starting from the four core services followed by some additional or external services which are integrated into the TOAR infrastructure.
2.1.1. TOAR Data Portal


The TOAR data portal is a WordPress website hosted by Xerb, the domain toar-data.org is owned by Forschungszentrum Jülich and linked to the instance at xerb.de. Xerb, as host, is taking care of backing up the WordPress instance with its database that is critical for the recovery of the website.
2.1.2. TOAR Database




The TOAR database is a PostgreSQL database with PostGIS extensions. The database server runs on a VM in the Helmholtz Data Federation (HDF) cloud (see Section 3 for details). The database structure (data model) is described in Metadata Reference. The database model is also available as schema dump on gitlab and the installation instructions are given in the README there.
Software for data ingestion consists of various Python programs which are available from the gitlab repository on request. The details of the ingestion workflow are given in The TOAR Data Processing Workflow. Data ingestion also makes use of geospatial information (station metadata). The management of geospatial data is described in Section 2.1.6 - Section 2.1.8.
For administrators: the TOAR database code is available from gitlab repository and the documentation from pages.
2.1.3. TOAR Web Services


The user-accessible web services of the TOAR Database Infrastructure consist of a REST API (https://toar-data.fz-juelich.de/api/v1 resp. https://toar-data.fz-juelich.de/api/v2) for machine access to the TOAR database and a GUI (https://toar-data.fz-juelich.de/gui/v1) 1 for interactive data analysis.
The REST API is written using the Python package fastapi (https://fastapi.tiangolo.com/). The source code can be found at the gitlab repository.
For the data processing and graphical analysis a standalone software package has been developed (toarstats) which is integrated with the TOAR V2 REST API (https://toar-data.fz-juelich.de/api/v2).
A special REST API service for flux-based vegetation damage assessment due to ozone based on the DO3SE model is currently under development. The beta version of its API can be accessed at https://toar-data.fz-juelich.de/do3se/api/v1/.
The TOAR V2 GUI is currently developed as a dashboard in Python with the help of plotly’s dash library. Leaflet and our local instance of the OpenStreetMap tile service described below are used for map displays.
2.1.4. TOAR Data Publications


The TOAR data publication service is realised as a python-tool for the TOAR data curators to prepare the data for publication, specifically to map the metadata to the schema used by B2SHARE. A specific community within the EUDAT B2SHARE instance has been created for TOAR publications (https://b2share.fz-juelich.de/communities/TOAR) and only the TOAR data curators have the right to publish in this B2Share community.
2.1.5. B2SHARE

B2SHARE is external to the TOAR Data Centre infrastructure and used by the data publication service. It is a trustworthy publication archive co-developed by leading European science institutions. The instance used by the TOAR Data Centre infrastructure is running on a VM also maintained at JSC. For the publications from the TOAR community a special community metadata profile has been generated and uploaded to the B2SHARE service. The metadata profile is available from https://b2share.fz-juelich.de/communities/TOAR.
For administrators: Information about B2SHARE can be found at https://www.eudat.eu/services/b2share; the server source code can be obtained from https://github.com/EUDAT-B2SHARE. Note, however, that registration as DOI registry is necessary with Datacite (https://datacite.org/dois.html) to deliver the full functionality of TOAR data publications.
2.1.6. GEO PEAS

GEO PEAS (GEOspatial Point Extraction and Aggregation Service) provides harmonised access to information from various geospatial datasets in aggregated form so that it can be included as metadata in the TOAR database or used in special analysis procedures. The GeoLocation service consists of a REST API which is written in Python with the Django web framework. The source code of the geolocation service can be found at the repository https://gitlab.version.fz-juelich.de/esde/toar-data/geolocationservices.
Note
This service runs behind a firewall and cannot be publicly exposed, because many earth observation (EO) datasets don’t allow open re-distribution.
The geospatial datasets which are processed by the GeoLocation service include a variety of EO datasets and vector data from a local instance of OpenStreetMap’s Overpass service (see below).
2.1.7. Rasdaman Array Database

The EO data which is analysed by the GeoLocation service is stored in a rasdaman array database (geoCube) which is for internal use only. For the complete list of data sources, version information and processing instructions refer to https://gitlab.version.fz-juelich.de/esde/toar-data/geolocationservices/-/wikis/Rasdaman-Data (access with JSC account).
2.1.8. OpenStreetMap Service

A local instance of OpenStreetMap’s (OSM) tile service is set up on the HIFIS (Helmholtz Federated IT Services) OSM Service VM. It is used to provide the map tiles on the GUI of the TOAR phase I web service (JOIN).
Overpass API is a read-only API that serves up custom selected parts of the OSM map data. It is implemented as part of the local OSM instance.
Nominatim geocoder uses OSM data to find locations on earth by name and address (from lat/long to location, revers lookup). The TOAR database infrastructure uses it for identifying the country and state where the station is located. It is installed together with the OSM tile service and uses PostgreSQL and apache.
2.1.9. Analysis Service
The user-accessible web services for analysis of the TOAR Database Infrastructure consist of a REST API (https://toar-data.fz-juelich.de/api/v2/analysis/) for machine access to the TOAR database.
The REST API is written using the Python package fastapi (https://fastapi.tiangolo.com/). The source code is currently not publicly available.
For the data processing a standalone software package has been developed (toarstats) which is integrated with the TOAR V2 REST API. The source code for the standalone software package can be found at the gitlab repository (https://gitlab.jsc.fz-juelich.de/esde/toar-public/toarstats).
The analysis services provide access to bulk time series downloads of time series as well as bulk aggregated time series downloads.
2.2. Server Environment
The TOAR database infrastructure is operated on different virtual machines hosted at JSC (Fig. 2.2). In addition to these VMs, the TOAR data infrastructure uses about >2 Terabytes disk space on the GPFS parallel file system of JSC and a similar amount of archive space on tapes. Backup copies are maintained at JSC and RWTH Aachen (see Section 2.3). Furthermore, the TOAR database infrastructure makes use of the B2SHARE service (administered outside of the TOAR Data Centre infrastructure, but also hosted at JSC).
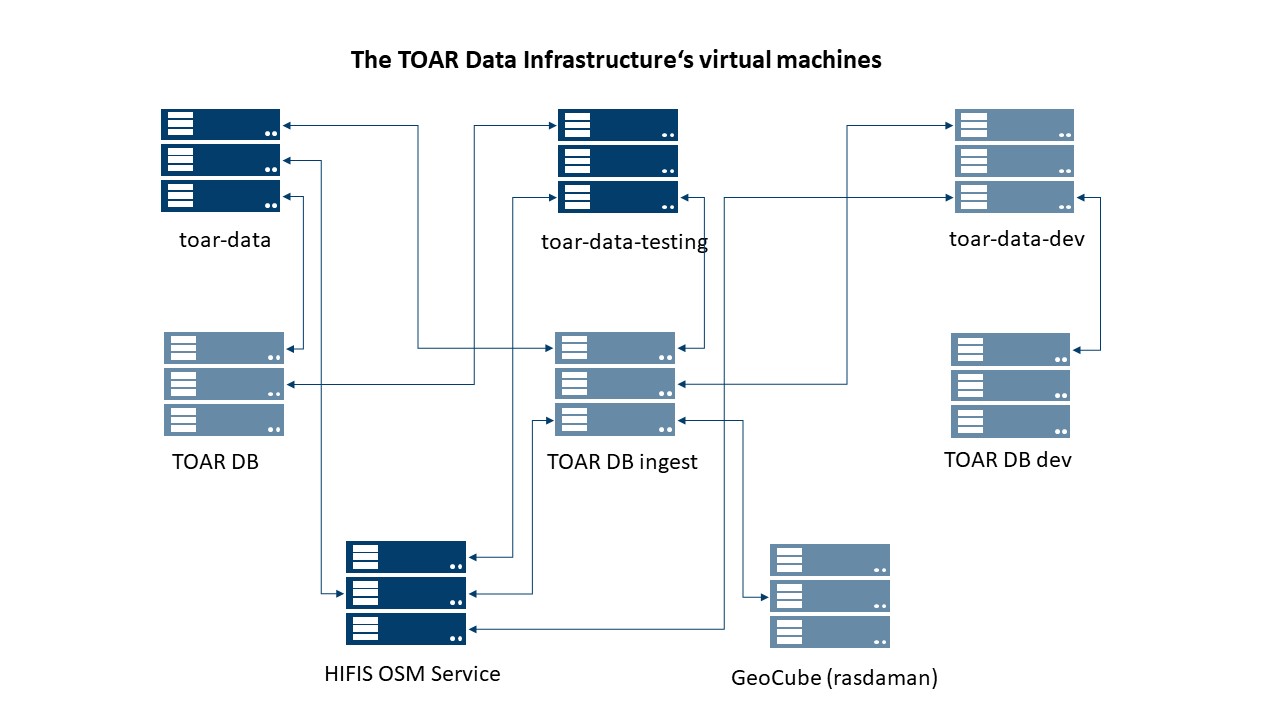
Fig. 2.2 Summary of TOAR-related VMs operated at JSC and the service relations between them; VMs accessible from outside JSC are in dark blue, the others are internal VMs.
Each VM is administered by a small number of JSC staff who are the only ones with ssh access to the system. The Openstack and VMware cloud infrastructures are also maintained by a small group of administrators, some of which also act as administrators for the TOAR VMs. The only systems which are accessible from outside JSC are the toar-data web server, the toar-data-testing instance, and the HIFIS OSM service.
The following table summarises the tasks of the virtual machines in the TOAR data infrastructure:
toar-data |
Interface (REST API) to the TOAR V2 database including the DO3SE web services 2 together with the interfaces (REST API and GUI) to the TOAR V1 database. |
toar-data-testing |
Open access instance to new versions (alpha and beta releases) of the GUI and REST API to allow for testing by the user community.\The configuration of this VM is kept as close to the operational toar-data VM to eliminate potential problems during the rollout of new software versions. toar-data-testing is also used to test new versions of the operating system and installed software packages with the operational version of toar-data, before these system-upgrades are rolled out on toar-data. |
toar-data-dev |
Internal use only; development instance for GUI, Rest API, statistics, do3se and GEO PEAS |
TOAR DB |
VM containing full functional, complete and operational database containing all TOAR V2 data.\The operational database contains a second schema for staging data where provider data can be stored for testing purposes, which are checked by the provider and released after the provider’s OK. |
TOAR DB ingest |
VM to particularly preprocess the data and stage it in a database which is set up similar to the operational DB. In addition, it contains a separate database for staging OpenAQ data.\All scripts for inserting data (individual submissions, harvesting, NearRealTime) into the production database should run from this machine. Apache Airflow 3 will be set up so that the UBA-NRT data can be processed via Airflow.\In addition, the GeoLocation service is running on this VM for verifying and adding location specific metadata. |
HIFIS OSM Service |
Lookup of locations; OSM Nominatim, OSM Overpass, OSM tileservice, postgresql, and apache are installed on this VM.\This service is primarily used by the HIFIS Community but is also used in the TOAR data preprocessing steps and by the GUI. |
TOAR DB dev |
This VM is set up “as equal as possible” (same operating system, same PostgreSQL version) to TOAR DB.\It can be used to test operating system/software upgrades to avoid surprises on the production system. On this VM there are two database instances “toardb-testing” and “toardb-dev”:\”toardb-testing” is set up to test database schema, operating system, posgresql version. It should not be too small to allow for performance testing. It must be clear to test users that toardb-testing is not an exact copy of toardb.\”toardb-dev” is, as the name suggests, a pure development database. |
GeoCube |
Internal use only; RASDAMAN array database with geolocation data used in the data ingestion process. |
A list of the installed software stack on each of the VMs listed above can be found in the Annex Section 5.
2.3. Data Locations and Backup Facilities
Each of the VMs is set up such that daily incremental backups are automatically created from all data belonging to the respective VM. JSC is using IBM Spectrum Prospect (has been known as Tivoli Storage Manager) for backup. The backup of TOAR DB is replicated to RWTH Aachen University’s computing centre. In addition, database dumps of the operational TOAR database (on VM TOAR DB) are taken annually and at certain events, for example when the database state is frozen to provide a consistent analysis base for the TOAR phase II assessment report. All database dumps will be accessible via B2SHARE. The code for setting up a new database instance and loading database dumps into this instance are provided publicly in the git repository including a (step-by-step documentation in the README.md file, see also Section 3 below).
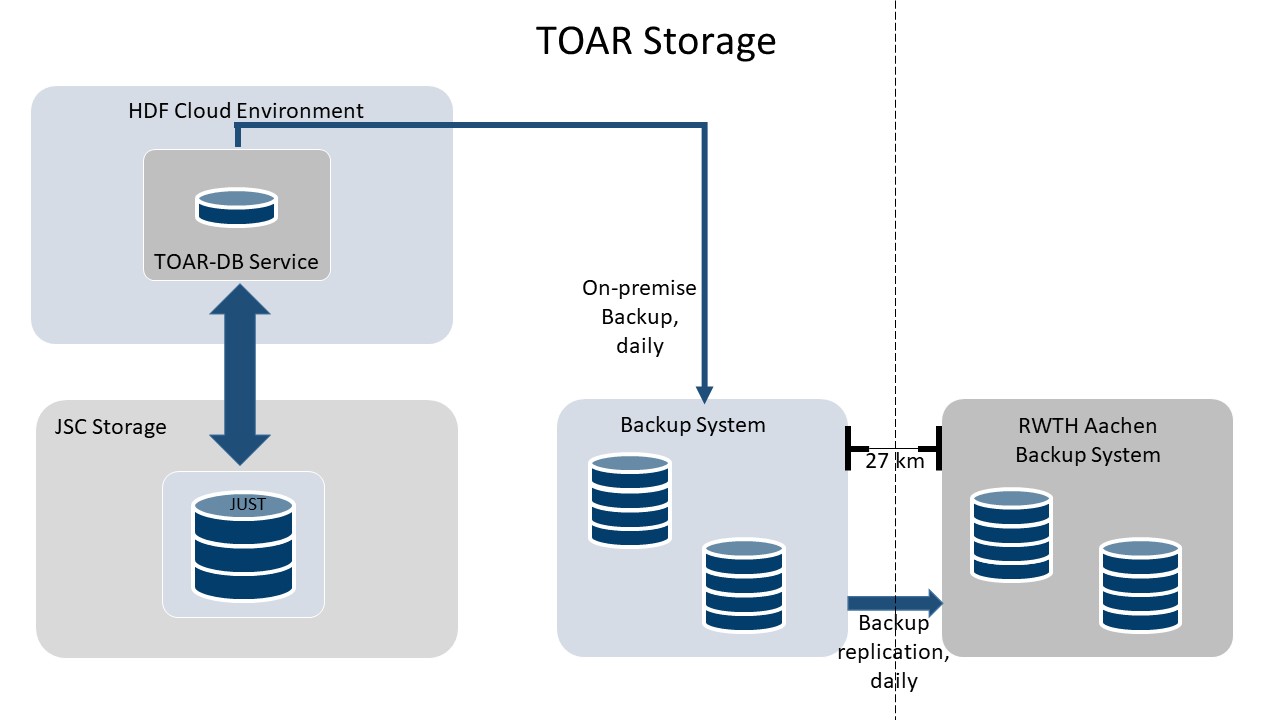
Fig. 2.3 Storage and Backup System
Raw data files downloaded from other air quality data archives or sent to the TOAR data centre by email are archived on tapes in the JSC archival storage. At least one additional copy is always available on a local PC or workstation.
Footnotes